OpenCloning
Introduction
OpenCloning is an open source DNA cloning tool integrated in eLabFTW. You should be able to access it directly from the Tools menu:
If the menu is grayed out, ask your Sysadmin to enable it. If you're looking for information about how to enable it as a Sysadmin, see installing OpenCloning section.
How to use
To learn about about the generic functionality of OpenCloning, please refer to the OpenCloning documentation. The application supports the following actions:
- Importing plasmid sequences from AddGene, iGEM distributions, etc., and genome sequences from NCBI.
- Loading your own sequence files.
- Planning cloning and designing primers using common techniques (Gibson, golden gate, gateway, etc.).
- Planning strain and cell line engineering using CRISPR and homologous recombination.
We cover the features specific to the integration of OpenCloning in eLabFTW in the following section.
See also the video below:
Loading resources into OpenCloning
Loading a sequence
To load a sequence in OpenCloning from eLabFTW, first create a resource entry of any type with a sequence file attached. The file can be in various formats, such as GenBank, FASTA, or SnapGene, or can be a JSON file created by OpenCloning (these files contain the cloning history).
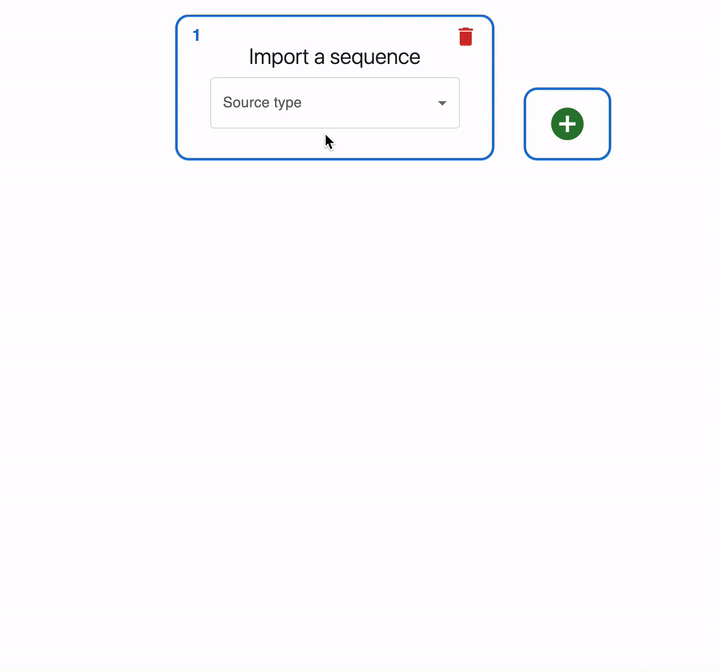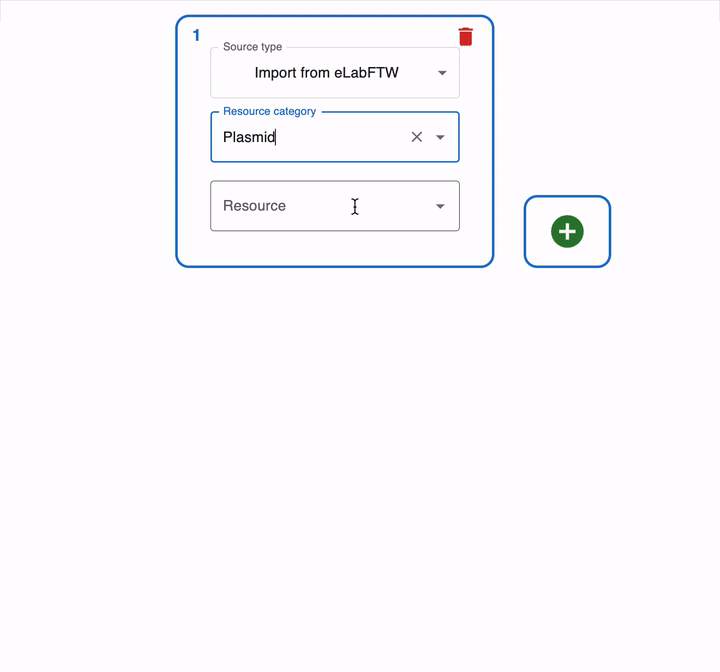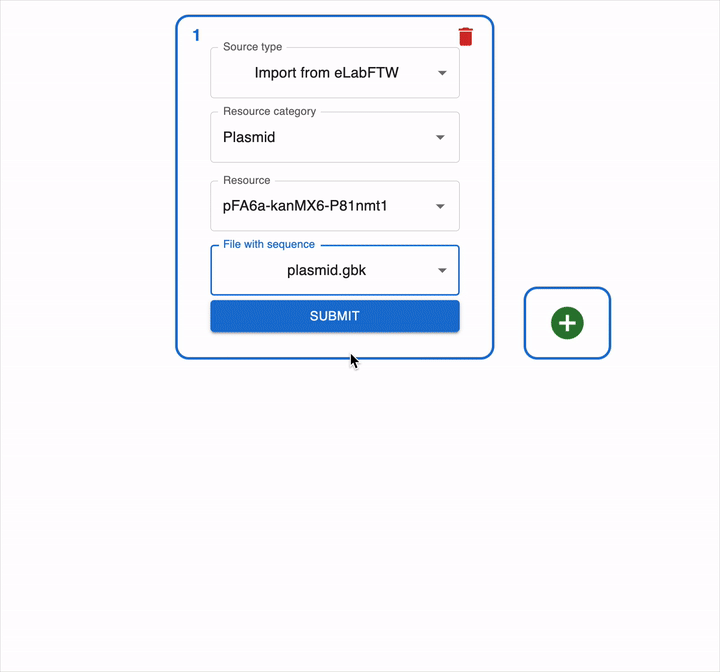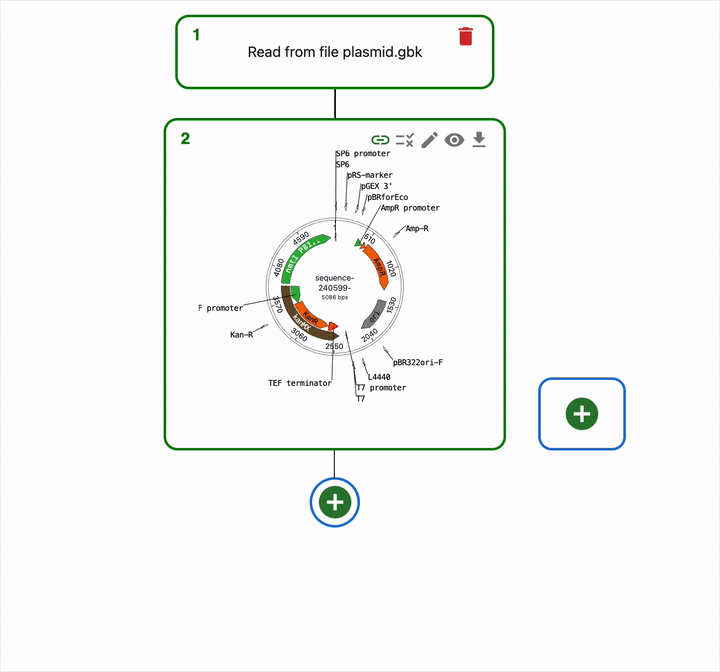
In the example below, we have created a resource entry of type Plasmid called pFA6a-kanMX6-P81nmt1 with a sequence file attached:
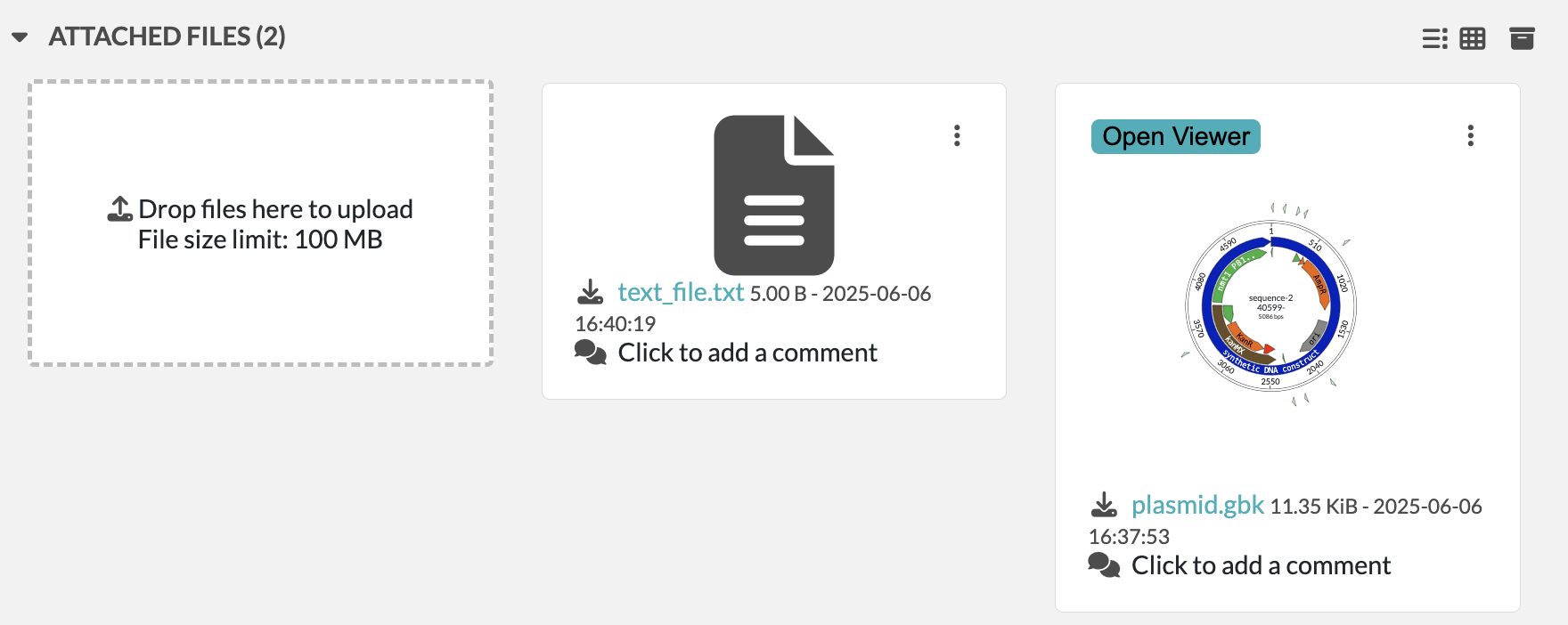
To load this file in OpenCloning, go to an empty source, click on Source type, and select Import from eLabFTW. Then, you can select the resource entry you want to load, and the file that contains the sequence.
If a resource entry was created using OpenCloning, you can load the JSON file instead, and the cloning history will be loaded automatically.
Loading a primer
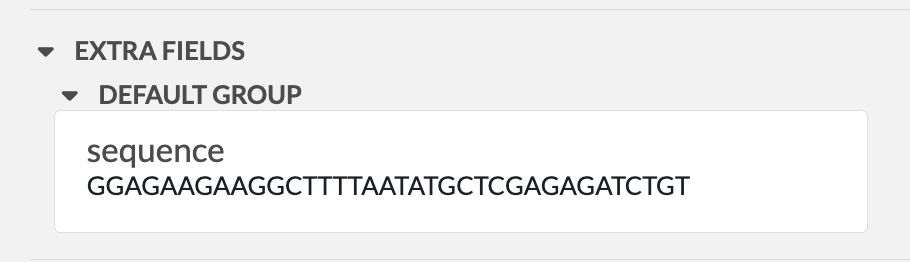
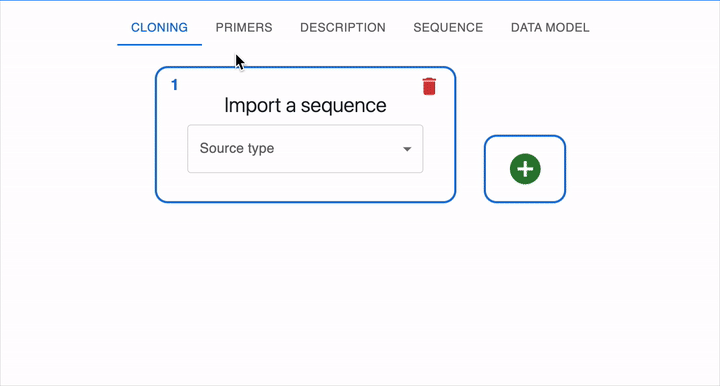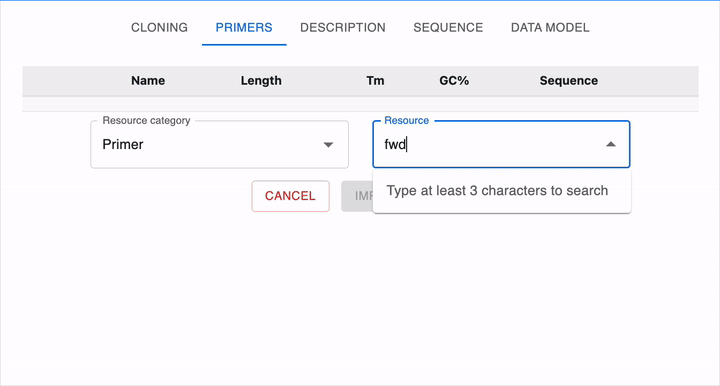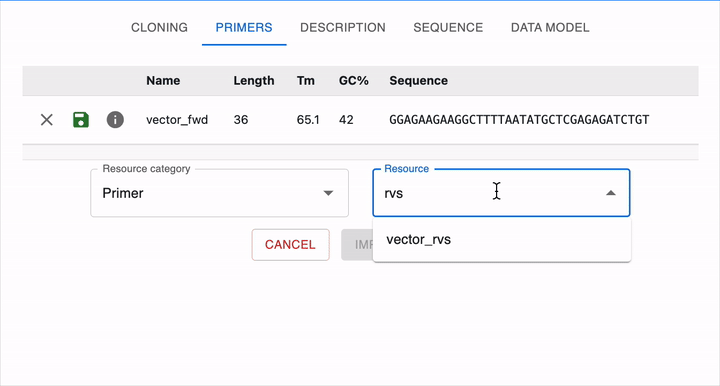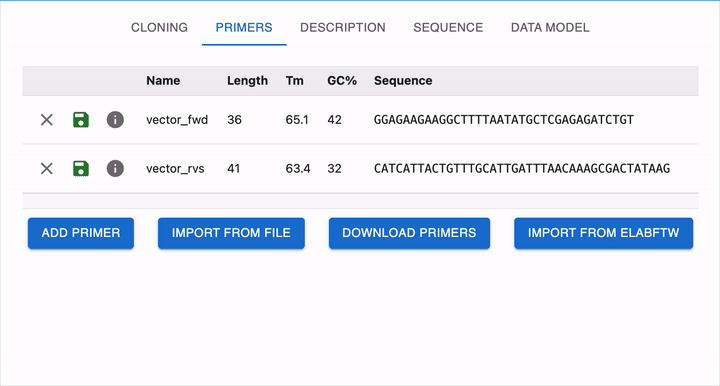
To load a primer in OpenCloning from eLabFTW, you need a resource entry that has a field named "sequence" containing the primer sequence. The sequence should be in plain text format and should only contain the characters ACGTacgt. The resource type does not have to be Primer, it can be any other type.
In the example below, we have a resource entry in eLabFTW with a sequence field containing the primer sequence:
To load it in OpenCloning, go to the Primers tab, click on Import from eLabFTW, and then select the resource entry you want to load. The sequence will then be displayed, and you can click on Import Primer to add it to the session. You can continue loading primers this way, and then close the import section by clicking Cancel.
Creating resources using OpenCloning
Creating a sequence
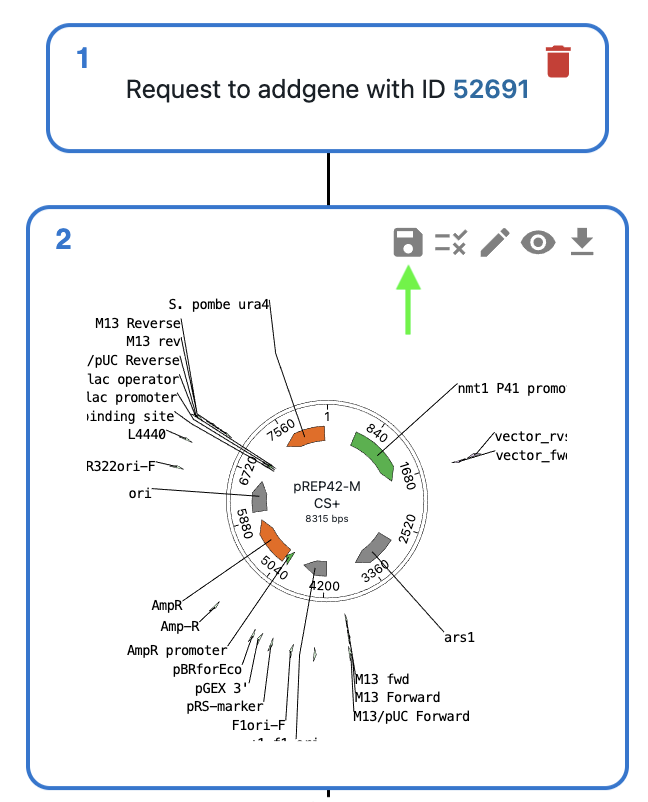
If you want to save a sequence from OpenCloning as a resource entry in eLabFTW, you can click on the floppy disk icon in the top right corner of the sequence view. There, you will be able to select the resource type and name.
When you save a sequence, a new resource entry is created with the following components:
- A GenBank file (.gb) containing the sequence and annotations.
- A JSON file containing the cloning history.
- Links to parent resources stored in the eLabFTW database (sequences and primers, if any).
The sequence border will turn green in the OpenCloning interface, indicating that it is saved in the eLabFTW database. Instead of the floppy disk icon, you will see a link icon. Clicking on this will open the eLabFTW entry in a new tab.
In addition, if your sequence used primers (e.g. if that sequence is a PCR product), OpenCloning will ask you to select a category to save those primers in the database.
- If you leave it empty, resource entries for the primers will not be created, but they will be stored in the JSON file, so they won't be lost.
- If you select a category, a new resource entry will be created for each primer with the same name as the primer in OpenCloning.
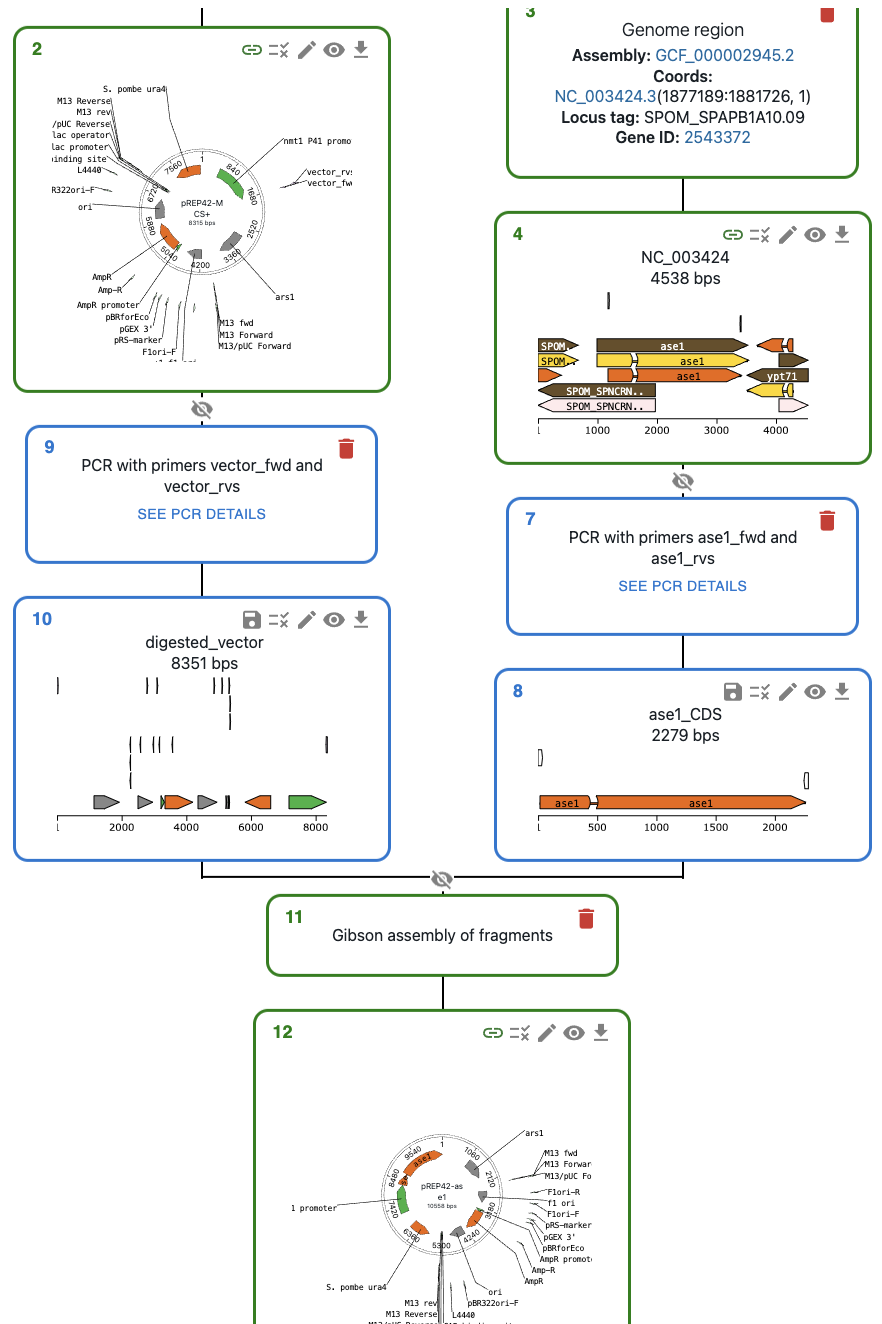
You might not want to save certain intermediate sequences as entries in the eLabFTW database (e.g. a PCR product that you used in a Gibson assembly). In that case, you can save the final product (The Gibson assembly product in the example below). The intermediate sequences will be stored in the JSON file, so they won't be lost. If you save only the final product, you will see that only the final product turns green.
Should I create sequence resource entries directly in eLabFTW or export from OpenCloning?
While both approaches work, creating resources in OpenCloning will automatically store provenance information. For instance, for plasmids from AddGene, the unique identifier will be stored. For genomic sequences, the assembly and sequence accession numbers will be stored along with the coordinates and gene identifiers. Even if you are loading a sequence from a file, you can drag-and-drop it into OpenCloning, and then save it as a resource entry.
Creating a primer
In addition to creating primers when you save sequences that use them (as above), you can also save primers by clicking on the floppy disk icon next to them in the OpenCloning interface.
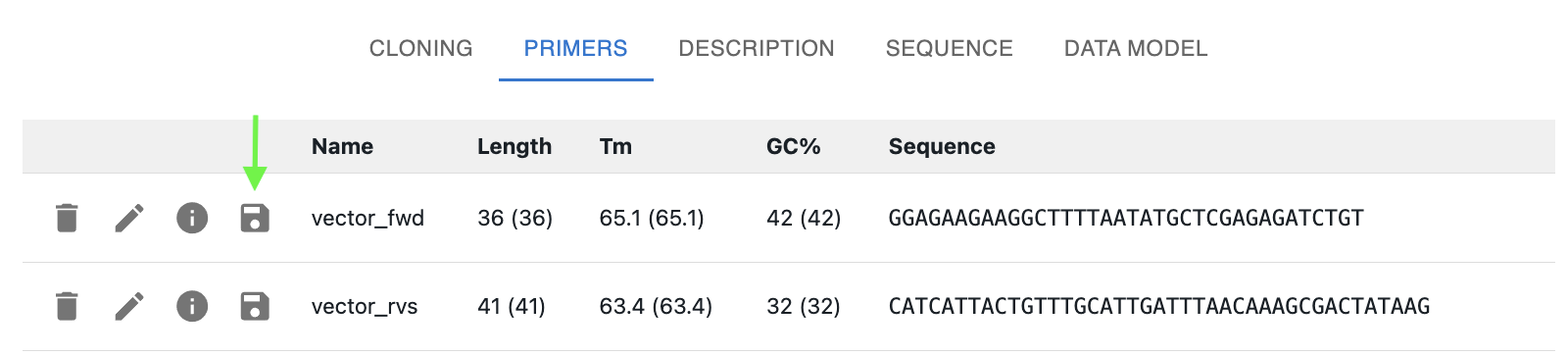
When you save a primer, a new resource entry is created with a "sequence" field containing the primer sequence. Once saved, you can no longer edit the sequence or name in OpenCloning. You will have to edit the sequence in the eLabFTW entry, and reload the primer in OpenCloning.
Removing resources from the session
OpenCloning cannot delete resource entries from the eLabFTW database. If you have saved a sequence or a primer in the database and you click on the delete icons in OpenCloning, they will be removed from the OpenCloning interface, but the resource entry will NOT be deleted.
Sequencing data
To load sequencing data from eLabFTW and align it to your resource sequence:
- Save your sequence as a resource entry in eLabFTW
- In eLabFTW, add the sequencing files to the resource entry (attach ab1 files, fastq files, etc.)
- Click on the
Verification filesicon on the top right of the sequence - Click on
Load from eLabFTW - Select the files that contain the sequencing data and click on
Load - Wait for the alignment to finish, then either click on
See alignments on editor, or click on the eye icon on the top right of the sequence to see the alignments.
Resource type organization
To manage plasmids and primers, follow the above instructions and OpenCloning will handle the relationships between the resources. If you want to represent cell lines and strains, we recommend the following configuration.
Create at least one resource type for each of the following (the names can be anything you want):
- Allele
- Locus
- Strain and/or cell line
Creating alleles
An allele is a variant of a gene. When describing the genotype of an engineered strain or cell line as text, we list the names of the alleles present in that strain or cell line that differ from the reference genome. We can do something similar in eLabFTW, while keeping track of the provenance of the alleles through links between resource entries.
Let's imagine we want to create a deletion allele for the gene ase1 in a strain of S. cerevisiae. One way to do this is through PCR and homologous recombination: we can use primers containing homologous arms to amplify a plasmid fragment containing a resistance marker, then transform the cells with this PCR product. If this is the first time you create an allele of the ase1 gene in OpenCloning, you can do this by:
- Loading the plasmid you will use from eLabFTW (if it's the first time you use it, load it from AddGene or other repository, then save it to eLabFTW).
- Loading the Genome region of interest in OpenCloning via
Genome region. - Designing primers containing homologous arms for the ase1 gene (you can do this directly in OpenCloning).
- Performing homologous recombination.
You should see something like this, where the plasmid is green (saved in eLabFTW) and the rest of sequences are blue (not saved yet in eLabFTW).
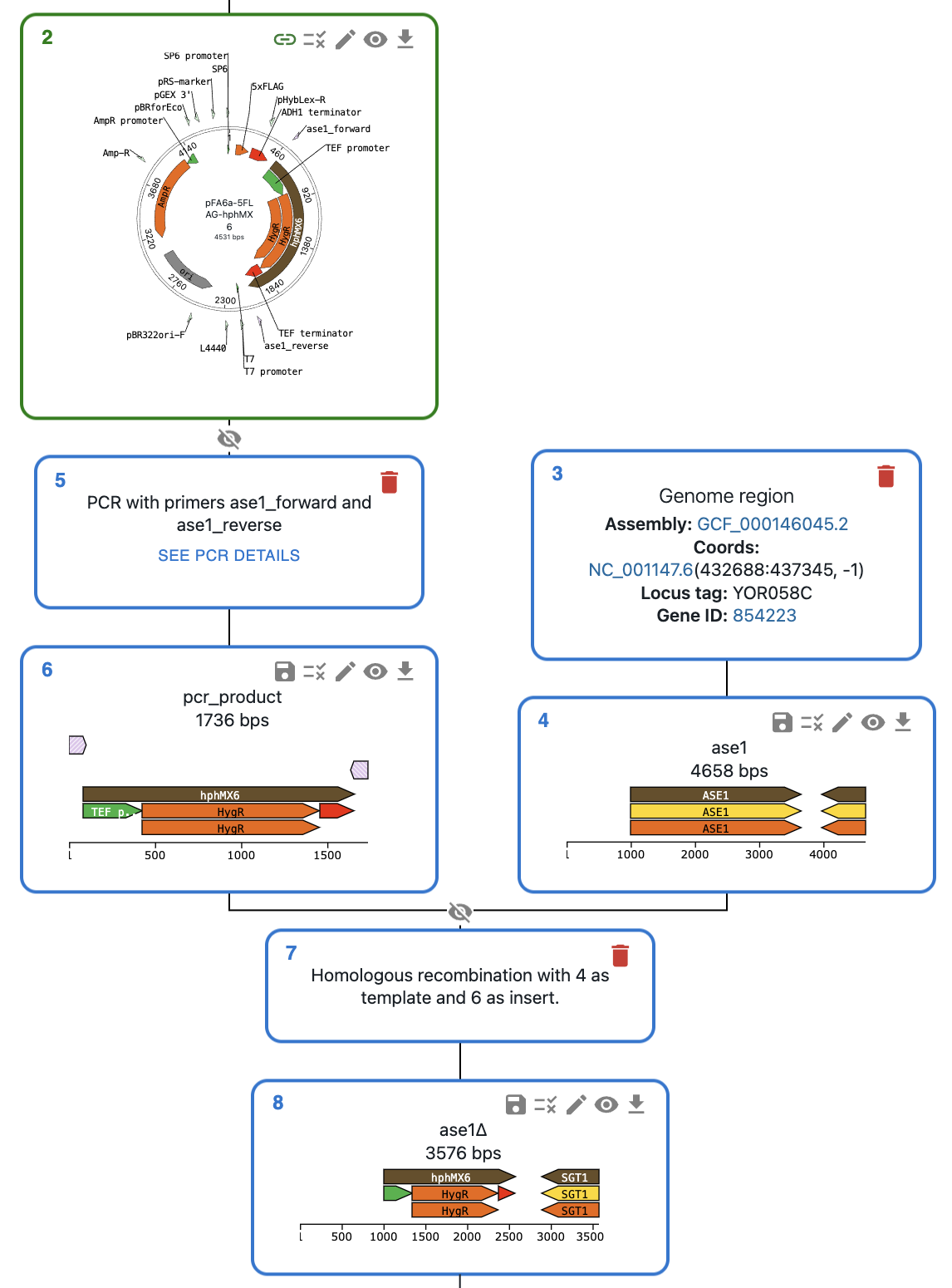
Then:
- Save the ase1 locus as a
Locusresource entry. - Save the allele as an
Alleleresource entry (you probably do not want to save the PCR product as its own entry, but you can if you want). Follow the nomenclature convention associated with your discipline for the name of the allele.
Now, whenever you want to create a new allele of the ase1 gene, instead of loading the genome sequence from the NCBI, load your ase1 locus resource entry from eLabFTW instead. This way, all of the alleles generated from this locus will be linked to the entry, and you can easily find them later.
When loading a locus in OpenCloning via Genome region, you can specify how many bases upstream and downstream of the gene you want to load. By default this is 1000, but you should increase it if you think you will use a larger region for cloning in this locus in the future, since you will keep using the same sequence for all the alleles generated from this locus.
Creating strains and cell lines
You must start with a reference strain or cell line. Create a resource, and ideally name it using a unique identifier (e.g. catalogue number in a stock center). You can also create a template for children strains / cell lines. It could be something basic like this:
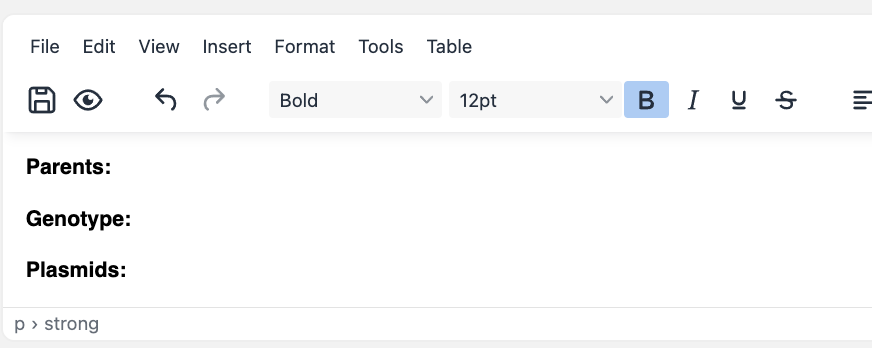
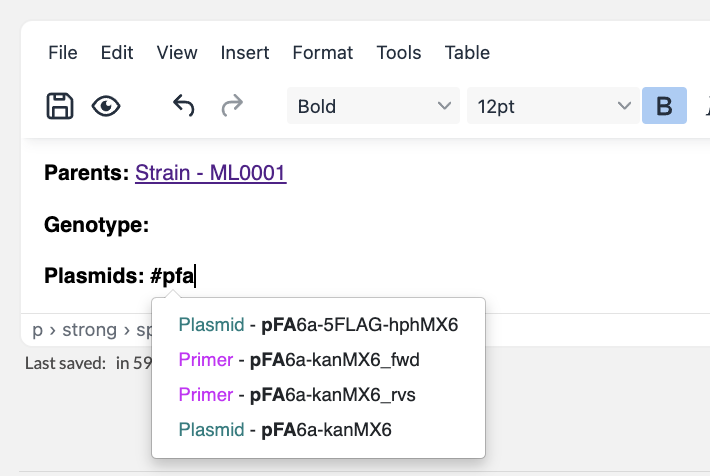
To represent a cell line / strain that has been transformed with a self-replicating plasmid, simply create a new cell line / strain resource entry, and mention the parent strain and transformed plasmid in the description (using #). This way, the resources will be linked to each other in eLabFTW.
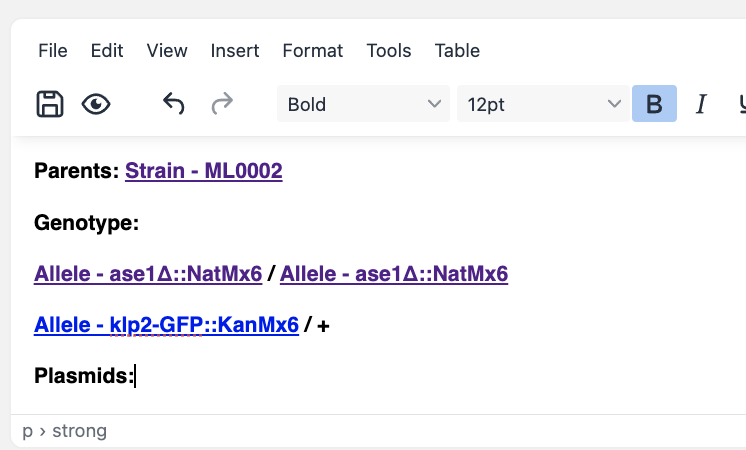
To represent the genotype of a strain / cell line that has been engineered, simply create a new cell line / strain resource entry and mention the parent strain and alleles in the description (using #). To represent a heterozygous genotype, you can use the + symbol (or whatever convention is followed in your discipline).
If you are creating new strains through mating, create a new entry referencing both parents, and include the alleles present in the resulting strain.